Personal tools
Document Actions
1.3 The Standard C Locale and the Standard C++ Locales




Click on the banner to return to the user guide home page.
1.3 The Standard C Locale and the Standard C++ Locales
As a software developer, you may already have some background in the C programming language, and the internationalization services provided by the C library. You may even be facing the problem of integrating internationalized software written in C with software in C++. If so, we recommend that you study this section. Here we give a short recap of the internationalization services provided by the C library, and its relationship to C++ locales. We then describe the C++ locales in terms of the C locale.
1.3.1 The C Locale
All the culture and language dependencies discussed in the previous section need to be represented in an operating system. This information is usually represented in a kind of language table, called a locale.
The X/Open consortium has standardized a variety of services for Native Language Support (NLS) in the programming language C. This standard is commonly known as XPG4. The X/Open's Native Language Support includes internationalization services as well as localization support. [6] The description below is based on this standard.
According to XPG4, the C locale is composed of several categories:
|
Category |
Content |
|
LC_NUMERIC |
Rules and symbols for numbers |
|
LC_TIME |
Values for date and time information |
|
LC_MONETARY |
Rules and symbols for monetary information |
|
LC_CTYPE |
Character classification and case conversion |
|
LC_COLLATE |
Collation sequence |
|
LC_MESSAGE |
Formats and values of messages |
The external representation of a C locale is usually as a file in UNIX. Other operating systems may choose other representations. The external representation is transformed into an internal memory representation by calling the function setlocale(), as shown in Figure 4 below:
Figure 4. Transformation of a C locale from external to internal representation
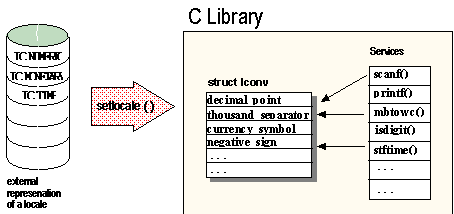
Inside a program, the C locale is represented by one or more global data structures. The C library provides a set of functions that use information from those global data structures to adapt their behavior to local conventions. Examples of these functions and the information they cover are listed in Table 2:
|
C locale function |
Information covered |
|
setlocale(), ... |
Locale initialization and language information |
|
isalpha(), isupper(), isdigit(), ... |
Character classification |
|
strftime(), ... |
Date and time functions |
|
strfmon() |
Monetary functions |
|
printf(), scanf(), ... |
Number parsing and formatting |
|
strcoll(), wcscoll(), ... |
String collation |
|
mblen(), mbtowc(), wctomb(), ... |
Multibyte functions |
|
cat_open(), catgets(), cat_close() |
Message retrieval |
1.3.2 The C++ Locales
In C++, a locale is a class called locale provided by the Standard C++ Library. The C++ class locale differs from the C locale because it is more than a language table, or data representation of the various culture and language dependencies. It also includes the internationalization services, which in C are global functions.
In C++, internationalization semantics are broken out into separate classes called facets. Each facet handles a set of internationalization services; for example, the formatting of monetary values. Facets may also represent a set of culture and language dependencies, such as the rules and symbols for monetary information.
Each locale object maintains a set of facet objects. In fact, you can think of a C++ locale as a container of facets, as illustrated in Figure 5 below:
Figure 5. A C++ locale is a container of facets
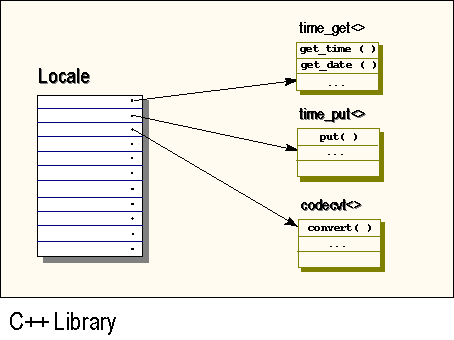
1.3.3 Facets
Facet classes encapsulate data that represents a set of culture and language dependencies, and offer a set of related internationalization services. Facet classes are very flexible. They can contain just about any internationalization service you can invent. The Standard C++ Library offers a number of predefined standard facets, which provide services similar to those contained in the C library. However, you could bundle additional internationalization services into a new facet class, or purchase a facet library.
1.3.3.1 The Standard Facets
As listed in Table 1, the C locale is composed of six categories of locale-dependent information: LC_NUMERIC (rules and symbols for numbers), LC_TIME (values for date and time information), LC_MONETARY (rules and symbols for monetary information), LC_CTYPE (character classification and conversion), LC_COLLATE (collation sequence), and LC_MESSAGE (formats and values of messages).
Similarly, there are six groups of standard facet classes. A detailed description of these facets is contained in the Class Reference, but a brief overview is given below. Note that an abbreviation like num_get <charT,InputIterator> means that num_get is a class template taking two template arguments, a character type, and an input iterator type. The groups of the standard facets are:
Numeric. The facet classes num_get<charT,InputIterator> and num_put<charT, OutputIterator> handle numeric formatting and parsing. The facet classes provide get() and put() member functions for values of type long, double, etc.
The facet class numpunct<charT> specifies numeric punctuation. It provides functions like decimal_point(), thousands_sep(), etc.
Monetary. The facet classes money_get<charT,bool,InputIterator> and money_put<charT, bool, OutputIterator> handle formatting and parsing of monetary values. They provide get() and put() member functions that parse or produce a sequence of digits, representing a count of the smallest unit of the currency. For example, the sequence $1,056.23 in a common US locale would yield 105623 units, or the character sequence "105623".
The facet class moneypunct <charT, bool International> handles monetary punctuation like the facet numpunct<charT> handles numeric punctuation. It comes with functions like curr_symbol(), etc.
Time. The facet classees time_get<charT,InputIterator> and time_put<charT, OutputIterator> handle date and time formatting and parsing. They provide functions like get_time(), get_date(), get_weekday(),etc.
Ctype. The facet class ctype<charT> encapsulates the Standard C++ Library ctype features for character classification, like tolower(), toupper(), isspace(), isprint(), etc.
Collate. The facet class collate<charT> provides features for string collation, including a compare() function used for string comparison.
Code Conversion. The facet class codecvt<fromT,toT,stateT> is used when converting from one encoding scheme to another, such as from the multibyte encoding JIS to the wide-character encoding Unicode. Instances of this facet are typically used in pairs. The main member function is convert(). There are template specializations <char, wchar_t, mbstate_t> and <wchar_t, char, mbstate_t> for multibyte to wide character conversions.
Messages. The facet class messages<charT> implements the X/Open message retrieval. It provides facilities to access message catalogues via open() and close(catalog), and to retrieve messages via get(..., int msgid,...).
The names of the standard facets obey certain naming rules. The get facet classes, like num_get and time_get, handle parsing. The put facet classes handle formatting. The punct facet classes, like numpunct and moneypunct, represent rules and symbols.
1.3.4 Differences between the C Locale and the C++ Locales
As we have seen so far, the C locale and the C++ locale offer similar services. However, the semantics of the C++ locale are different from the semantics of the C locale:
The Standard C locale is a global resource: there is only one locale for the entire application. This makes it hard to build an application that has to handle several locales at a time.
The Standard C++ locale is a class. Numerous instances of class locale can be created at will, so you can have as many locale objects as you need.
To explore this difference in further detail, let us see how locales are typically used.
1.3.4.1 Common Uses of the C locale
The C locale is commonly used as a default locale, a native locale, or in multiple locale applications.
Default locale. As a developer, you may never require internationalization features, and thus never set a locale. If you can safely assume that users of your applications are accommodated by the classic US English ASCII behavior, you have no need for localization. Without even knowing it, you will always use the default locale, which is the US English ASCII locale.
Native locale. If you do plan on localizing your program, the appropriate strategy may be to retrieve the native locale once at the beginning of your program, and never, ever change this setting again. This way your application will adapt itself to one particular locale, and use this throughout its entire run time. Users of such applications can explicitly set their favorite locale before starting the application. Usually the system's default settings will automatically activate the native locale.
Multiple locales. It may well happen that you do have to work with multiple locales. For example, to implement an application for Switzerland, you might want to output messages in Italian, French, and German. As the C locale is a global data structure, you will have to switch locales several times.
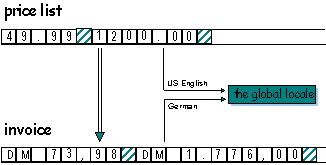
Let's look at an example of an application that works with multiple locales. Imagine an application that prints invoices to be sent to customers all over the world. Of course, the invoices must be printed in the customer's native language, so the application must write output in multiple languages. Prices to be included in the invoice are taken from a single price list. If we assume the application is used by a US company, the price list will be in US English.
The application reads input (the product price list) in US English, and writes output (the invoice) in the customer's native language, say German. Since there is only one global locale in C that affects both input and output, the global locale must change between input and output operations. Before a price is read from the English price list, the locale must be switched from the German locale used for printing the invoice to a US English locale. Before inserting the price into the invoice, the global locale must be switched back to the German locale. To read the next input from the price list, the locale must be switched back to English, and so forth. Figure 6 summarizes this activity:
Figure 6. Multiple locales in C
Here is the C code that corresponds to the previous example[7]:
double price;
char buf[SZ];
while ( _ ) // processing the German invoice
{ setlocale(LC_ALL, "En_US");
fscanf(priceFile,"%fl",&price);
// convert $ to DM according to the current exchange rate
setlocale(LC_ALL,"De_DE");
fprintf(invoiceFile,"%f",price);
}
Using C++ locale objects dramatically simplifies the task of communicating between multiple locales. The iostreams in the Standard C++ Library are internationalized so that streams can be imbued with separate locale objects. For example, the input stream can be imbued with an English locale object, and the output stream can be imbued with a German locale object. In this way, switching locales becomes unnecessary, as demonstrated in Figure 7:
Figure 7. Multiple locales in C++
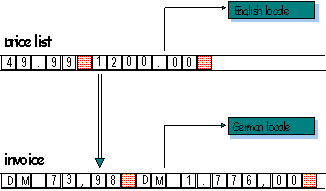
Here is the C++ code corresponding to the previous example:
priceFile.imbue(locale("En_US"));
invoiceFile.imbue(locale("De_DE");
double price;
while ( _ ) // processing the German invoice
{ priceFile >> price;
// convert $ to DM according to the current exchange rate
invoiceFile << price;
}
Because the examples given above are brief, switching locales might look like a minor inconvenience. However, it is a major problem once code conversions are involved.
To underscore the point, let us revisit the JIS encoding scheme using the shift sequence described in Figure 2, and repeated below. With these encodings, you will recall that you must maintain a shift state while parsing a character sequence, as shown in Figure 8:
Figure 8. The Japanese text encoded in JIS from Figure 2
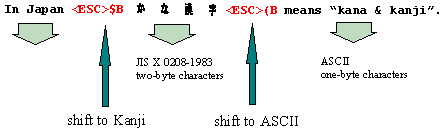
Suppose you are parsing input from a multibyte file which contains text that is encoded in JIS, as shown in Figure 9. While you parse this file, you have to keep track of the current shift state so you know how to interpret the characters you read, and how to transform them into the appropriate internal wide character representation.
Figure 9. Parsing input from a multibyte file using the global C locale
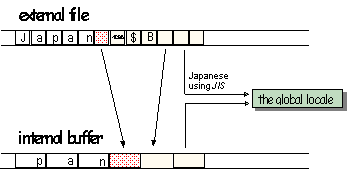
The global C locale can be switched during parsing; for example, from a locale object specifying the input to be in JIS encoding, to a locale object using EUC encoding instead. The current shift state becomes invalid each time the locale is switched, and you have to carefully maintain the shift state in an application that switches locales.
As long as the locale switches are intentional, this problem can presumably be solved. However, in multithreaded environments, the global C locale may impose a severe problem, as it can be switched inadvertently by another otherwise unrelated thread of execution. For this reason, internationalizing a C program for a multithreaded environment is difficult.
If you use C++ locales, on the other hand, the problem simply goes away. You can imbue each stream with a separate locale object, making inadvertent switches impossible.
Let us now see how C++ locales are intended to be used.
1.3.4.2 Common Uses of C++Locales
The C++ locale is commonly used as a default locale, with multiple locales, and as a global locale.
Default locale. If you are not involved with internationalizing programs, you won't need C++ locales any more than you need C locales. If you can safely assume that users of your applications are accommodated by classic US English ASCII behavior, you will not require localization features. For you, the Standard C++ Library provides a predefined locale object, locale::classic(), that represents the US English ASCII locale.
Multiple locales. Working with many different locales becomes easy when you use C++ locales. Switching locales, as you did in C, is no longer necessary in C++. You can imbue each stream with a different locale object. You can pass locale objects around and use them in multiple places.
Global locale. There is a global locale in C++, as there is in C. You can make a given locale object global by calling locale::global(). You can create snapshots of the current global locale by calling the default constructor for a locale locale::locale(). Snapshots are immutable locale objects and are not affected by any subsequent changes to the global locale. Internationalized components like iostreams use it as a default. If you do not explicitly imbue your streams with any particular locale object, a snapshot of the global locale is used.
Using the global C++ locale, you can work much as you did in C. You activate the native locale once at program start--in other words, you make it global--and use snapshots of it thereafter for all tasks that are locale-dependent. The following code demonstrates this procedure:
locale::global(locale("")); //1
_
string t = print_date(today, locale()); //2
_
locale::global(locale("Fr_CH")); //3
_
cout << something; //4
| //1 | Make the native locale global. |
| //2 | Use snapshots of the global locale whenever you need a locale object. Assume that print_date() is a function that formats dates. You would provide the function with a snapshot of the global locale in order to do the formatting. |
| //3 | Switch the global locale; make a French locale global. |
| //4 | Note that you need not explicitly imbue any streams with the global locale. They use a snapshot of the global locale by default. |
1.3.5 Relationship between the C Locale and the C++ Locale
The C locale and the C++ locales are mostly unrelated. However, making a C++ locale object global via locale::global() affects the global C locale and results in a call to setlocale(). When this happens, locale-sensitive C functions called from within a C++ program will use the global C++ locale.
There is no way to affect the C++ locale from within a C program.
©Copyright 1996, Rogue Wave Software, Inc.